29 Oct 2015
Today. Today was pretty epic. That is, I spoke to so many folks, all of whom are doing interesting things. Which, I suppose can be said for a lot of cons, but alas, there was a level of depth, meaning, and caring in today’s talks. A level of fluidness as topics moved from tech related things to random other things.
This morning I was joined for a run by a co-racker (co-worker?), and headed off in a different random direction. Towards the end of said run, we passed the Icelandic embassy, and then stopped to pray in a temple that’s been standing since the 15th century. It was nuts.
After said run and some stretching, we did the book-signing thing again:

From there, I spent quite a bit of time on the ‘hallway’ track. Topics and individuals ranged. From Burnout in IT, to new vSensei mentors, an inordinate amount of time trying to understand the habits of the ‘high performers’ in our spheres, to the esoteric details of archival quality forensically sound engineering notebooks, OpenStack Israel, and IPv6 headers that can be adapted for use with Cloud (Service, Tenant, User, and how that can be set as destination headers to help protect the PII in transit), with some time spent planning a major 30-in-30 event, and OpenStack Tokyo, and and and. I’m sitting here 22 hours after I woke up to day, and, well, it doesn’t feel like there is much chance of stopping yet.
Lunch, dinner, all an impressive a blur of amazing conversations. and, with luck, lots of things to come.
28 Oct 2015
Day number 1, or my second day in Tokyo started a bit early, but, that worked out well, as I managed to get a good feel for the city by taking a quick jog around:



From there, the Summit started in ernest.
Day 1 Keynote
Rather than a live blog or some running notes with commentary, I’ll just call out a few highlights:
Day 1 Book Signing

Book signings I’ve done in the past have lasted 10-15 minutes, and generally ran through a few hundred books in that time. This time we came prepared, with what feels like 500+ books each day of the summit:

Of course the action shot has me not doing any work:

The line, it was huge. Hi Mom.

After this, was a lunch chosen by menu pictures, and a LOT of #vBrownBag sessions.
27 Oct 2015

Hooray! I managed to get from the airport to the hotel without getting lost, and/or dead. That has to be a good thing, right? Once in the hotel, knocked out registration. It was quick and painless, however I imagine today (Tuesday, because temporal things in blog posts can be interesting), it’ll be insane just prior to the keynotes.
As it was late, and I had no desire to have a brownout during book signing today, I had dinner with the #vBrownBag crew at a French restaurant. Yes yes, French food in Tokyo. Today, today local food shall be had.
For the rest of today: Keynote, book signing, #vBrownBag, and lots of sessions.
14 Oct 2015
Words of warning. This is one of those long winded rambling posts. There will be good bits here and there (at least that is the hope), but, this doesn't follow good SEO, or copywriting practices. There is no real call to action, no clear intent or message.
On most school days, I’ve taken to walking my now five year old to school. It’s a wonderful way to spend an extra few minutes with each other, and the walk is therapeutic in other ways. That is, its good for all the reasons walks are good: extra exercise, being outside, being mindful / present, and all that. Todays walk was extra special, that is, it triggered this long running train of thoughts on technical debt, and what we leave behind each time we say “Fuck it, Ship it” or we open a firewall port for expedience, cut a corner on an implementation or design due to some arbitrary constraint.
That is, I had this conversation:
Context: The traffic officer / crossing guard was not yet on duty.
5: "Dad, where's that man?"
Me: "Oh, he isn't here yet. Where do you think he is?"
5: "He's at the Tuna Sammich store."
Me: "Tuna Sandwich?"
5: "He went to the Tuna store to get a Tuna Sammich for his butt."
Me: "His butt?"
5: "His Right Butt Cheek. He needs a Tuna Sammich for his right butt cheek."
Me: "..."
You can see how this is sort of therapeutic, a small smile crosses our faces. His at having said butt cheek a few times in a row and gotten away with it. Mine from the innocence, the oddity of it, and most of all, because he said butt cheek. (One can’t be an adult /all/ the time).
It did however, hit me with a pang of guilt. One that is familiar to all parents, I imagine. That is, it was the realization that eventually, he’ll grow up. We won’t walk as much, and while we’ll still talk, it likely won’t have this level of random innocence to it (tho, I’ll be damned if I’m not going to strive for that).
That pang of guilt, by way of a long ass introduction, led me to thinking about what sort of future, what sort of legacy we’ll be leaving to them. I’m not one for thinking too long about the huge parts of legacy, things like the environment or economy and all. Instead, I’m speaking of what sorts of technical legacy we’re leaving around. What the impact is, each time we make a decision, and what that will look like in 10, 15, 20 years time.
Oh, I hear you saying: “No system I build will be online in 15 years.” or “My field expedient Perl code will be re-factored during the next release.”, and lots of other things to the same effect.
These two examples were drawn from my own career. The first one from a middling FiServ (hard to gauge size when small is 5mm and large is multi-trillion). That FiServ was (still is) running an HP MPE/iX system. This system had been stood up when 9GB SCSI drives were amazing. When you were hired on, you heard about how the system came to be, and how much they spent on it, etc. What I didn’t realize at the time, is I was also hearing why it would never change, but that is another story. That system, whilst they’ve added layers and layers of middleware, online services, and the like, is still online, and still has active contracts for 4 hour drive replacement, on 9GB scsi drives.
Think for a minute, at the middling FiServ size, what else might be done, if one weren’t spending a considerable effort maintaining what was ultimately a decision made in haste. One that the presiding admin (architects weren’t really a thing then) decided would be fixed on someone elses watch?
The other example, field expedient Perl, is one that I’ve found almost everyone has an example of in their career. While not 15 years back, I can almost guarantee said code is still running in some class 3 telco switch somewhere. This particular gig, I got from some connections on IRC, it was to work on networking and voice gear for a local telco. Knowing nothing about switching, routing, voice, or really, networking, I figured… why the hell not.
At some point, it came about, that some code my predecessor wrote needed to be updated. Some file format changed or, as the comments in the code I found said: “Some asshat put something in the file they weren’t supposed to”. So, what’d I do? I ghetto patched the crap out of it. To date, if you call one of a few South Florida prefixes, the metadata is routed through that code.
So the point, I suppose to all of this ranting and raving in this post, is pay attention to even the little decisions, and what sorts of impacts they’ll have. Because while we’re doing a decent job on the front end of educating the little IT folks of the future with things like Scratch, RaspberryPi, and all sorts of STEAM groups, 3d printing, etc etc. We’re can do a better job in leaving good systems for them to inherit.
16 Sep 2015
In working through a few iterations of what I’m now calling the #vSensei mentorship program, a number of common themes have come up. One of those is reading. Lots and lots of it, in fact. What follows here are the most common recommendations reading I give, some general, some not so general.
General
In here fall books for finding time, getting moving, working on bigger ideas, and the like.
A note on that last one: It is neither self-help, nor management, nor ideas. Rather, a massive tome on tactics and counter tactics used in Guerrilla warfare. It’s huge, uses more formal English, and is awesome for extrapolating ideas out and into your day to day operations, be they startup, or career specific.
One of the common themes encountered as part of the #vSensei program has been that of “I would like to become $x” where $x is some flavor of architect, vcdx, or similar. The books here, aren’t technology specific. Rather, they are to help you open your mind to thinking about how things are designed. This helps for building products to building supportable, rugged infrastructures, that will actually be used:
Quazi Technical
These two both talk process, improvement, and the like. One being much more technical than the other:
Summary
This is the start of what should be an ever growing book list.
16 Sep 2015
In our small sphere of the world, we are tasked with the ever daunting task of keeping up. Keeping up with the tools, processes, techniques, thought processes, and technologies of our craft. Each of these is changing at an ever accelerating pace, and keeping up can end up being a full time job. What follows are some thoughts on how to use the various mediums at our disposal to quickly assimilate large quantities of new information. Additionally, some techniques for acquiring levels of depth, as needed.
Knowledge Acquisition Process
As one’s career progresses you find that the requirement for breadth in your knowledge does as well. That is, you will be rapidly, and a times violently, drawn from one subject to another, with very little time or warning. Other times, you will need to get extremely deep. For me a three pass method seems to work best.
- Skim
- Targeted Depth
- ‘Real’ Depth
Each step has it’s own benefits. Skimming will get you up to speed quickly. Targeted depth lets you pull out parts relevant to the tasks on hand, and gain additional depth, as needed. ‘Real’ depth, is akin to the 10,000 hours phenomenon. That is, at step 3, there is a level of deliberate, ongoing practice.
It should be noted, that often times, one doesn’t get past the first two steps. Business needs change, your level of interest changes, squirrel, and then some.
It should be noted that acquiring worthwhile sources is an endeavor all it’s own. That is, this post assumes you have already selected a topic or topics and some of the source materials you will need to power through.
Skimming
Depending on how bad or how often you squirrel, skimming is where you will spend most of your time. So, it’s important to know how to do it properly. First, let’s start with a definition, and then move into how to apply it to both written materials and audio / video.
Skimming, in this context, is the rapid consumption and partial assimilation of a data source, or bit of content. Specifically, skimming in this context is meant to serve as a first pass on materials, allow you to gain a general familiarity, and to highlight any areas of interest for later consumption.
Update: On Skimming vs Speed Reading. Remembering our goal for assimilating information, is comprehension and retention, rather than speed.
Written Material
Most technical books, blog posts, and the like all follow a very familiar format. That format is amazingly similar to an outline. That is:
- Title
- First heading
- Second heading
- Some words
- possible subsection
- Other words
- and so forth
These landmarks provide a roadmap for both finding and consuming information.
The Procedure:
Note: For more depth on skimming.
As a general rule, keep a notepad, post-its, or something of the like nearby to take note of interesting areas and what to come back to. Another point, if you do happen on a super interesting paragraph or three, go ahead and read them. Just recall that this first pass is to help build out a generalized familiarity, and plan for later.
- Read the Table of Contents.
This will give you a high level overview. It will also let you pick and choose the most relevant chapters and decide a reading order.
- Read the headers.
Passing over the headers will help build a quick reference in your mind, of what is available, what you can come back to, etc.
- Read the first and last sentence of each paragraph.
Whilst this one seems a bit odd, do it. This will let you take a note if the section needs to be come back to when in the targeted phase.
- Read the call out boxes.
There is something in these call-outs that the author wants you to pay attention to. Often times, this is where said authors real-world experience shines through. I’ve picked up may a time saver in call out boxes.
- Do the same thing for figure captions.
- Finally, read over the code examples if relevant.
Audio / Video
Audio / Video material is a bit harder. Things like podcasts, YouTube, Computer Based Training, and the like don’t often lend them selves to skipping around. In this case the strategy that works best for me is keeping a notebook handy, and playing said source back at 1.5 - 2x speed. Often times in the background. As you are listening, your ears will perk up when something interesting comes up. At that point, pause, write it down, rewind, and watch that spot at normal speed.
Targeted Depth
This is where things get interesting. That is, now that you have skimmed the material and have written down a number of spots to come back to, it’s time to gather some targeted depth. At this point, you should have a passing familiarity with the topic at hand, and a good understanding of what areas you need to go deeper on first. In the targeted depth phase, in addition to reading, we begin to add hands on exercises. This process isn’t as well defined, but generally goes something like this:
- Go back and read the entire section (section, chapter, etc.)
- Setup a ‘lab’ and do any examples presented in the material.
- Failing that, or in addition to, attempt to come up with your own labs.
- Find additional resources, blogs, forum posts, community experts, consume their materials. Do the labs.
- Repeat for each section and item you wrote down.
‘Real’ Depth
Even more than targeted knowledge in a subject area, ‘real’ depth begins once you have progressed through passing or even deep knowledge in a few areas into the “Trough of Disillusionment”:
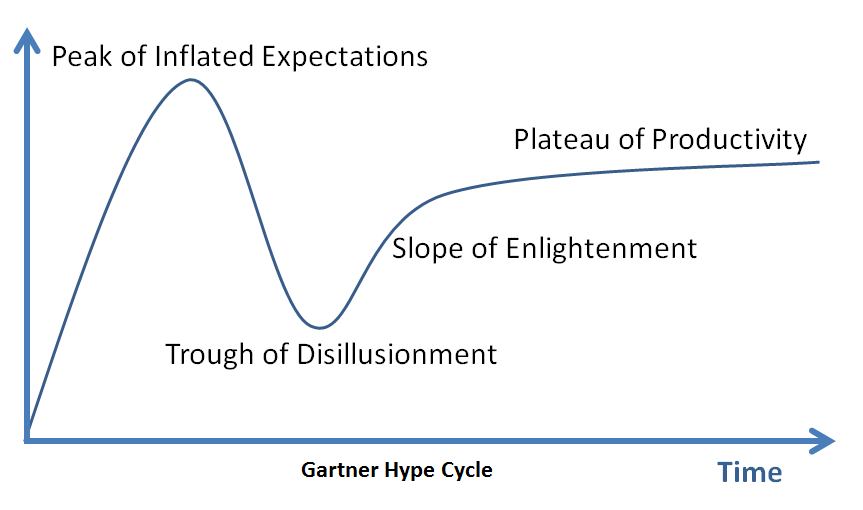
Once you’ve hit the trough, you begin to get an idea of how much more there is to know before you reach a true level of expertise.
Note: One can be called and expert, and many are, well before you get to the end of this path. However, as someone who pursues learning, you will know there is a big difference between ‘expertise’ and Expertise. That is what I’m talking about here. More on this concept here.
This phase, will encompass all of the prior phases. That is new source materials, skimming, depth, repeat, repeat, repeat. Along the way, some teaching will be done. Some skilled work, etc.
Summary
This post has been wordy. Very, Very wordy. Having read it over a number of times, I think it puts some methodology behind the madness that is the lifelong learning you signed up for when you jumped into IT. A lot of this won’t be new, but mayhaps there is a tidbit here or there that will help make your processes more efficient. If you have questions, comments, or want to add your own experiences & processes, drop me a line on twitter.
14 Sep 2015
Day .5? Day 0? Something like that. The Reckoning, a who’s who of the various movers and shakers in ‘the community’, put on by John Troyer and his wife Kat Troyer. Unlike the big conferences, The Reckoning is not in support of any given vendor, or to drive any specific technology. Rather, it is aimed at community and professional development.
Day .5 - Unconference

The day .5 unconference got the event under way. We started with 10-15 minutes of finding topics of interest to those in attendance. Which wasn’t all that hard once we got moving. From there, we broke into two smaller discussion groups, and things really got moving.
While one could list in bullet points the various things that were talked about, I think that would fail to catch both the energy and genuine sentiment of those present. On the whole, professional development, transitioning from engineering to management, mentorship, and the like… all front of mind for those in attendence.
Day .5 - Dinner / Speaker 1 Kurt Collins
After the unconference broke up, and then into even smaller discussion groups, dinner was served. Lots of great conversations. At my table specifically, a discussion or two about roosters, quasi-therapeutic retention techniques (Origami, graphic not taking, etc). We also spent quite a few minutes on bitcoin and tdcs.
After dinner, we returned to the front room where we met Kat Troyer who led us in a small, but important grounding / mindfulness exercise. We also touched on the code of conduct, and the spaces built into the schedule to take care of ones self. As an introvert, I can’t tell you how important this is, vs some of the larger conferences.
After the introduction, John introduced us to Kurt Collins. Done interview style, John interviewed Kurt on stage. First talking about some of Kurt’s background, his first Atari, Commodore, and how he got his start into programming. From there the conversation drifted into the evolution or tipping point. That is technology / code is eating the world. One no longer hails a taxi, you call an Uber from your phone. You can order dinner from Amazon, and more. That led into a discussion of how if one is in a tradition IT shop, how do you yourself cross the gap, and how do you help your organization do the same?
We then spent some time talking to Kurt about his nonprofit effort, the Hidden Genius Project, an amazing project, geared at training and mentoring black male youth in technology creation, entrepreneurship, and leadership skills to transform their lives and communities. He shared what could have been a horror story. That is, a change pushed to ‘production’, 3 minutes before an investor demo. shudder. Kurt and his cofounders realized the change broke the application, however, instead of fixing it, they let the kids use their soft skills to work around it in their pitch, which went off well.
Day .5 - Geek Whisperers
The Geek Whisperers, a great little podcast, got up on stage and closed us out. They chatted about the conference itself, the unconference, and then we shared stories. Stories of when we needed a mentor, when we took a leap, and more.
Day .5 - Summary
All and all day .5 (day 0? day 1?) was a new and wonderful kind of interesting.
29 Aug 2015
This started as a series of VMworld protips, however, they apply equally well to most tech conferenes. These are pulled directly from my tweet stream, without much in the way of context:
- VMworld ProTip: Lost gadgets happen. Put some contact info on your backgrounds: http://graphicssoft.about.com/od/iphoneandipodtouchapps/ss/Wallpaper.htm be prepared to remote wipe.
- VMworld ProTip #24: Netflix, Spotify, etc… don’t be that dude on the wifi…
- Nigel Hickey @vCenterNerd: #VMworld ProTip #769: Get your spouse/partner setup with @spousetivities. Don’t lock them up in the hotel, please. Let them explore too!
- VMworld ProTip #25: USPS “If it fits it ships” boxes are your friends on the return trip.
- VMworld ProTip #47: Everyone has a plan till they show up. Schedule works as a high level guide, but VMworld happens.
- VMworld ProTip #94: No, that isn’t a free wifi network. Tunnel like a mofo.
- VMworld ProTip #93: Practice Good charging hygine: https://lockedusb.com/ and others.
- VMworld ProTip #92: Always Be Charging, and if you’ve extra: share.
- I am John White @johna_white #VMworld ProTip #8675309: Don’t stare at your phone or tablet before the session, say hello to your neighbor.
- VMworld ProTip #33: Again on people: Do Not eat alone. Also do not eat with your travel group. Meet people, share war stories, etc.
- Scott S. Lowe @scott_lowe RT @cody_bunch: #VMworld ProTip #31: Help people. < FTFY :-)
- Nigel Hickey @vCenterNerd #VMworld ProTip #768: Spend time in the Hang Space and do not skip that. Great place to network with friends & find new ones! //@cody_bunch
- VMworld ProTip #52: The community has a lot of micro-celebs. Don’t be afraid to introduce yourself to that blogger you’ve followed for ever
- VMworld ProTip #32: On the people part, meet, connect, and follow-up with at least three. Build your own micro-community.
- VMworld ProTip #31: Everyone there knows something you don’t. The inverse is also true. /Help/ people.
- VMworld ProTip #92: Pace yourself, and make time for yourself. Go for a walk or nap if you need to get away.
- VMworld ProTips? ProTip #48 - Bring cough / vitamin C drops. You will need them.
08 Aug 2015
In April this year, I kicked off a ‘Mentorship Program’, and while I don’t much like the title of program, as that tends make one think it’s more formal than it really is, I think it’s time I kicked up and invited in another round of folks into the program.
First some background:
The Program
For what is left of 2015, and maybe a bit more, I’ll ‘mentor’ you towards some end of your choosing. Be it professional, personal, or both. In practical terms, this means at a minimum this means: 1 hour a week on Skype (hangouts, phone, etc) to talk about where you are currently, what you are working on, etc.
These are 1 - to - 1 mentorships, that is, you and I working on helping you get to that next step.
Class H2 - 2015
Ok, so we’re starting late to be calling it H2, as there is just under 5 months left in the year. But, who knows, we did huge things last round in just three. So, This ‘class’ if that’s what we’ll call it, will again be five individuals (you are likely one of them), who would like some help, advice, a coach / mentor (it is a mentorship program, no?). You are currently thinking about, or looking to work on that next thing, or need a push to help you get to that next level career wise. Whatever it is, I’m here to help.
You
Having described it some in the prior paragraphs, the only real qualifiers for you are:
- You have to be willing to hustle, to do things, to make changes
- Don’t be an asshole
- Have some way for us to get in contact on the regular.
Me
Why do this with me? Umm, well, I do things, and over the past few rounds have helped a few handfuls of folk get down their path as well.
Selection Process
Well, here’s the kicker. The selection process, if there are more than 5 sign-ups, involves me looking over the applications, reading a bit about you, and perhaps asking some additional questions.
Overflow
In case there are more than 5, what do? In that case, after I have done a first round of selections, I will send out emails notifying everyone, and asking for permission to share your information with other folks who would also make good mentors. It would then be between y’all to sort out the details from that point.
Application
The application!
That’s all there is to it. Disclaimer: It’s a Google form, who’s only recipient is me (insofar as these things can be guaranteed).
03 Aug 2015
Another post inspired by ask.openstack.org
The question was:
If there are two instances(os:nova:server), how can I specify the boot order?
The Heat Orchestration Template, or HOT, specification provides a ‘depends_on’ attribute, that works generically on Heat resources. That is, depends_on a network, depends_on another instance, database, Cinder volume, etc.
In the OpenStack docs they provide the following example:
resources:
server1:
type: OS::Nova::Server
depends_on: server2
server2:
type: OS::Nova::Server
Or for multiple servers:
resources:
server1:
type: OS::Nova::Server
depends_on: [ server2, server3 ]
server2:
type: OS::Nova::Server
server3:
type: OS::Nova::Server
